Traditional data stacks can be expensive to build and run and - for a large majority of start-ups and businesses - it can be prohibitive to operate. A key hallmark of the Modern Data Stack is composability, interoperability, and dynamic pricing based on usage. Long gone are the days of monolithic servers running in on-prem servers. However, in our experience, not all technology choices are equal in terms of cost, and for most small data teams, we’ve settled on a suite of tooling that reduces the total cost of ownership while allowing for future growth.
We call this the “Lean Data Stack”. This gives our clients almost exactly the same business value but at a lower barrier to entry, and can be implemented in a single sprint. This is likely not the best choice for more mature businesses or ones with established engineering teams, but we’ve found even in these situations picking from this suite of products means the data team can start leveraging the benefits of the platform much earlier in our engagement.
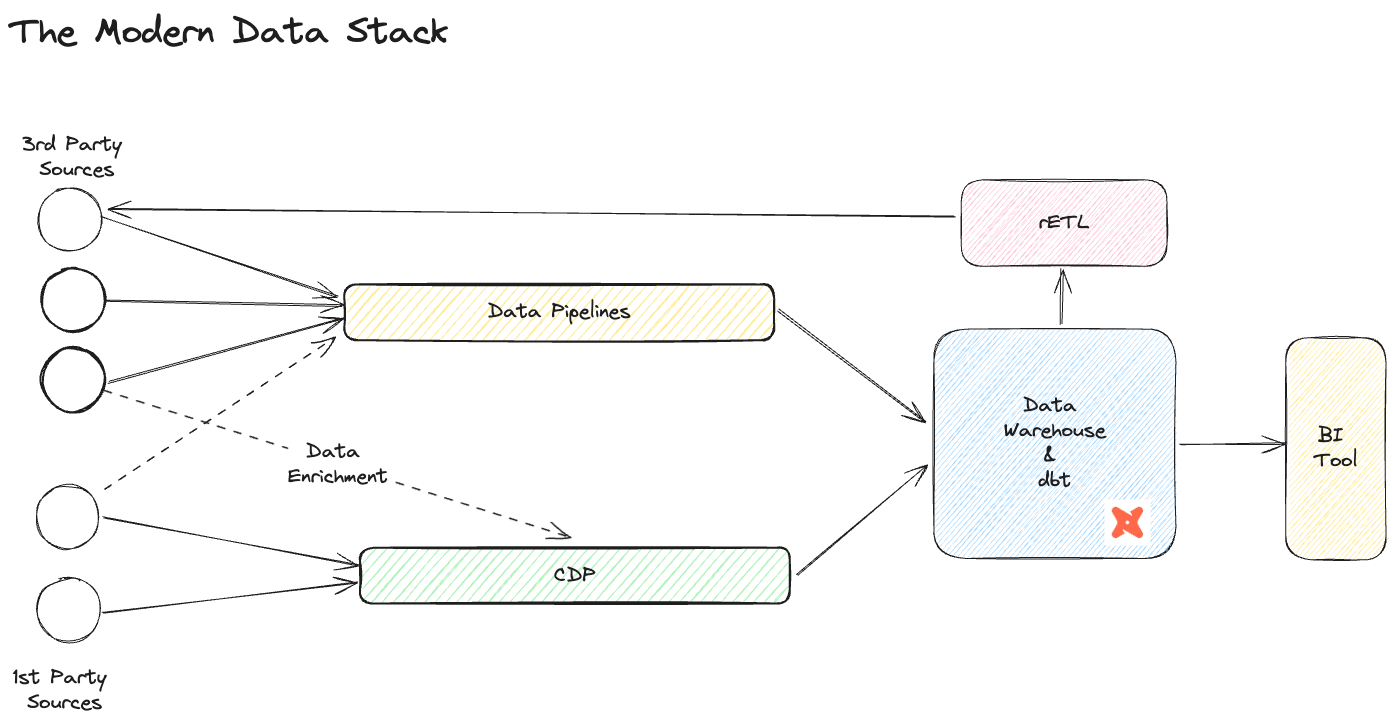
The Modern Data Stack
The modern data stack is an assembly of core components that facilitate the centralisation, democratisation and activation of data. Rather than a monolith service, the MDS is a collection of managed services, custom technologies and bespoke engineering that allow a company to leverage the power of data with smaller teams. The needs, sophistication and maturity of the business influence technology choice and there is a wealth of tried and tested choices available to make up the modern data stack. Our version of this stack includes:
- Data Pipelines: Used to move data from source systems to data storage
- Data Storage: Where to house your analytics data
- Transformation engine: The technology used to process data
- Business Intelligence tool: How to display the data and tell a story to end users
- Customer Data Platform: CDP to help create a single customer view and track key operational events
- Reverse ETL: Pushes the cleaned, verified, trusted, and enhanced data back into source systems for further activation.
The Lean Data Stack
This is a suite of technologies that deliver the ideals of the MDS at a fraction of the cost. It favours managed and third-party services over bespoke ones. Over the last two years, many of these services have focussed on interoperability so setting up the platform can be done quickly and at a relatively low cost. This unlocks higher value data work earlier in our engagement such as data modelling, event tracking implementation, reporting and metrics, insight generation, enabling self-serve analytics and data activation.
Core Components and Recommendations
Data Pipelines
We recommend a flexible approach when settling on a data collection strategy. Where possible, choose a managed service instead of building and maintaining any custom connectors. This allows anyone on the data team to manage data pipelines, and required updates - due to an API change, for example - are handled for you. This alleviates the maintenance burden on client engineers and removes requirements for specialist knowledge on orchestration and data engineering.
The key 3rd party systems we consider for every data source are Fivetran, Stitch and Airbyte. Generally, if a “good enough” connector exists in Stitch or Airbyte we will choose that over Fivetran. This flexible approach can save thousands of dollars over a year and comes with only a slight overhead in management as there may be two ETL tools in play on a client stack. Honourable mention to Snowflake’s Snowpipe feature which can ingest files from cloud object stores such as AWS S3 and GCP Cloud Storage.
Data monitoring and observability can be achieved through a number of third-party tools, such as Elementary, Metaplane, or Sifflet (and you can expect to see more solutions maturing in this space in 2024). Alerts and alarms all piped into Slack, Teams or email - depending on client choice.
Transformation Engine
Depending on client engineering capabilities our recommendation is dbt Cloud or self-hosted dbt-core plus an orchestration engine. dbt has been a game changer in the analytics world and has successfully introduced common software engineering practices such as version control, code reuse through macros, documentation, testing and orchestration into the data world. It is implemented in a huge number of companies and puts control of data transformation back into the hands of the data team.
The dbt Cloud option is the right choice for businesses that have single-person or small data teams. It reduces the overall management of the transformation engine to just the data modelling component and, like the managed pipeline service, reduces the operational burden.
Where there is a larger team or at least one engineer, the cost overhead for dbt Cloud can be reduced further. At Tasman, we have a mature serverless implementation of dbt-core that can run on any cloud platform and costs peanuts to run (more information to come in a follow up article). An orchestrator is required to trigger dbt runs and to handle failures. We’ve implemented quite a few, and our favourites are Prefect, Dagster, and AWS Step Functions.
Data Storage
We favour using data warehouses over data lakes for data analytics workloads as the cost of storage has reduced so much in recent years and the technology and features have matured to such an extent that it can be used to run ML/AI workloads. The data warehouse is the heart of the LDS, it is the central and singular source of truth and allows maximum flexibility for data teams to evolve their data modelling and activation strategies. By using the data warehouse to store raw and curated data it reduces vendor locking to any one third-party tool and also allows an open and secure environment for the data team to investigate, experiment and build.
Snowflake is our go-to choice because of its common-sense defaults, cost-management strategies, out-of-the-box optimisations, and enhanced feature set.
BigQuery is a worthy choice and is more cost-effective if the client is already on GCP. This is due to the wealth of internal connectors between Google products that are either free or very low cost. But it does push the responsibility on the developer’s shoulders to implement proper clustering techniques to avoid inefficient and costly data scans.
BI and Reporting Tools
PowerBI, Looker and Tableau are undeniably the industry incumbents, of these we generally recommend Looker (if budget allows). For more constrained budgets we’ve been recommending Holistics. We’re big fans of it because of the pricing model, already a great implementation of the usual features and continuous development of new ones.
Customer Data Platforms
Really the two platforms we recommend here are driven by business requirements and capabilities of the engineering team. Rudderstack is the go-to choice for robust CDP for most organisations: it is a fully managed service and has a good ecosystem of connectors. Implementation of the SDK is relatively simple and we’ve found it’s very quick to set up.
Snowplow is our go-to recommendation for clients who need more sophisticated or general event platforms with high availability and fault tolerance. Proper setup and management usually require more commitment from the engineering team.
Both offer robust products that have a host of integrations, allowing to seamlessly move data between systems. Other common features include simple data pipelining, granular event routing, customer profiling, native integration with data warehouses, and reverse ETL.
Event Governance
Though not a part of the traditional MDS, we always combine a way to manage tracking plans when implementing CDPs. There really isn’t any other product that comes close to Avo for this, although Rudderstack’s Data Quality Toolkit does look like a good initial step into this space and their roadmap aims to enable feature parity.
Reverse ETL
Once you have cleaned, transformed and validated your data, reverse ETL tools can be used to push it back into source systems. This means that you can extract even more value from your data than just reporting. Key use cases include customer profiling, predictive lead scoring and campaign personalisation. For this use case, we recommend Hightouch as it is robust, cost-effective and easy to set up and manage.